生成MD5值相同的文件
编译md5collgen源码
使用md5collgen工具生成两个前缀相同的文件
echo "Message prefix" > prefix.txt./md5collgen -p prefix.txt -o out1.bin out2.bin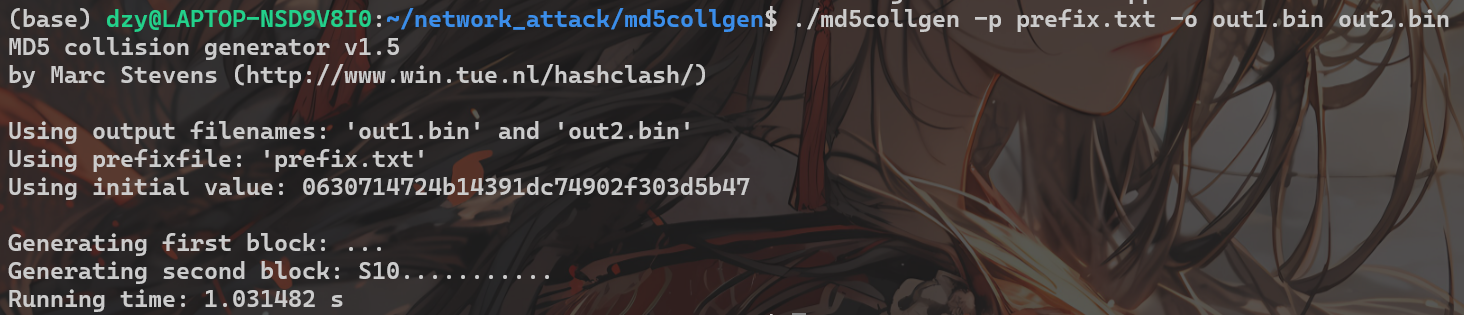

文件md5相同
使用bless查看文件内容
out1.bin

out2.bin

可以看到文件前缀内容相同,后续内容不同,但md5值仍然相同
长度延伸
echo "Message suffix" > suffix.txtcat ./out1.bin suffix.txt > out1_long.bincat ./out2.bin suffix.txt > out2_long.bin

文件md5依然相同
生成两个MD5值相同但输出不同的两个可执行文件
编译下述程序
#include <stdio.h>unsigned char xyz[200] = { 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'B'};int main(){ int i; for (i=0; i<200; i++){ printf("%x", xyz[i]); } printf("\n");}gcc ./Lab3_task2.c使用bless查看二进制内容
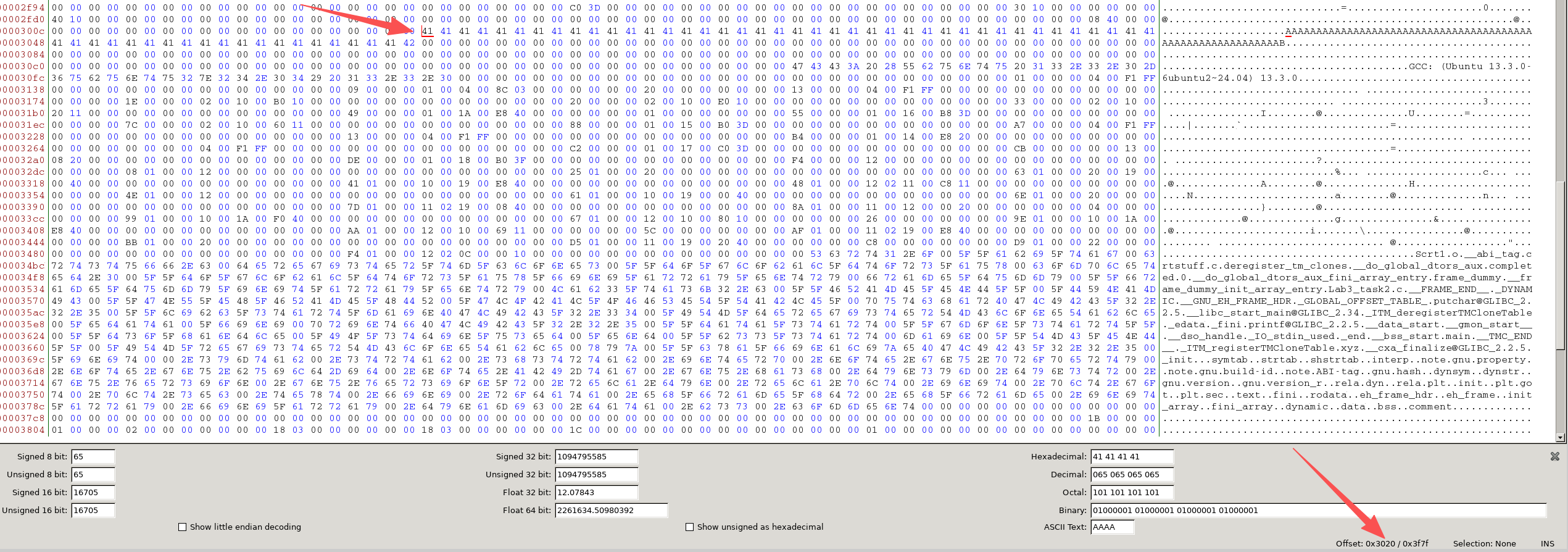
定位到字符串开始位置在0x3020偏移处,结束位置在0x305b
截取到0x3040处,将前缀内容输出到prefix文件中
head -c 12320 a.out > prefix截取后缀内容,即0x305b(取值不唯一,拼接后不破坏ELF文件基本结构即可)后的内容
tail -c +12380 a.out > suffix然后对 prefix 生成 md5 相同的两个文件
../md5collgen/md5collgen -p prefix -o prefix1 prefix2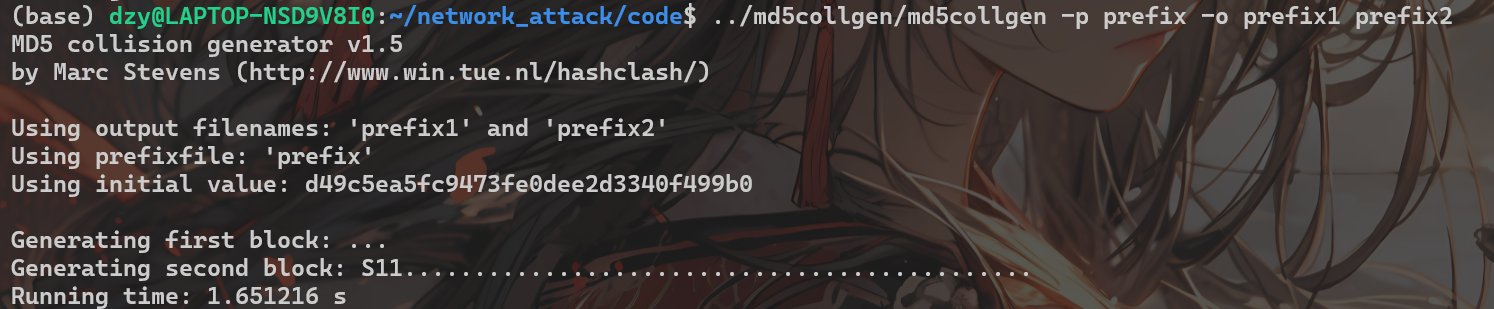
把刚刚的后缀接到这两个文件后面
cat suffix >> prefix1cat suffix >> prefix2运行程序,发现输出内容不同


但md5值相同

生成两个MD5值相同但代码行为不相同的可执行文件
构造origin.c文件如下:
#include <stdio.h>unsigned char a[200] = { 'B', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'B'};unsigned char b[200] = { 'B', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'B'};int main(){ int i; int isSame=1; for(i = 0; i < 200; i++) { if(a[i]!=b[i]) isSame=0; } if(isSame) printf("run benign code\n"); else printf("run malicious code\n");}编译:
gcc -o origin origin.c查看文件内容
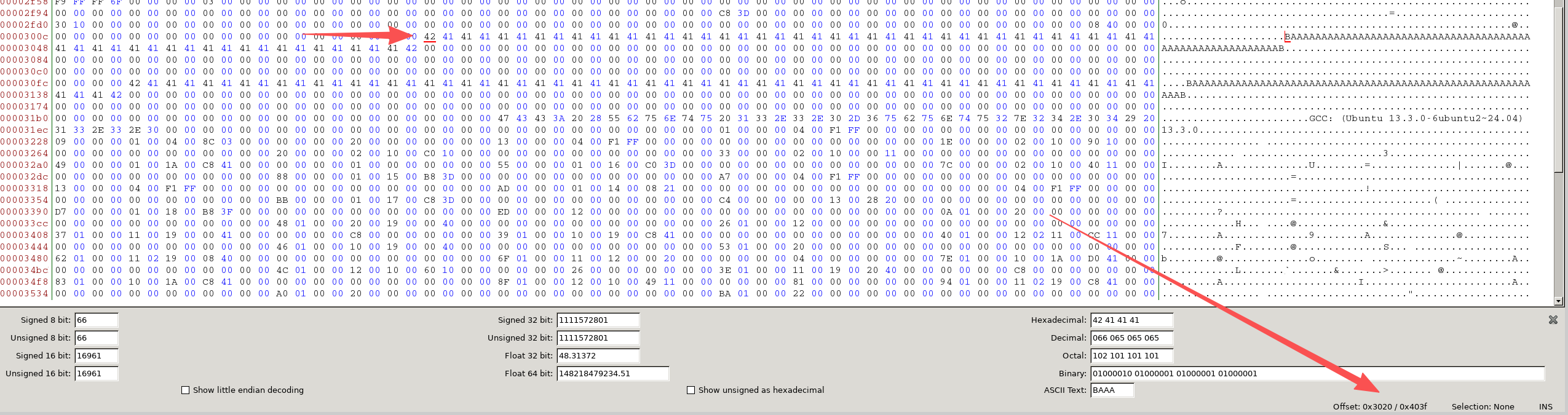
0x3020为第一个字符串的内容,0x3100为第二个字符串的内容
截取12340前的内容
head -c 12340 origin > prefix生成MD5相同的两个文件
../md5collgen/md5collgen -p prefix -o prefix1.bin prefix2.bin截取prefix1中生成的字符串内容
tail -c +12321 ./prefix1.bin > middle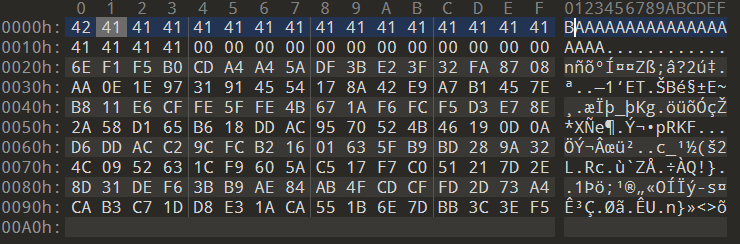
截取ori中第二个字符串后面的内容
tail -c +12745 ./origin > suffix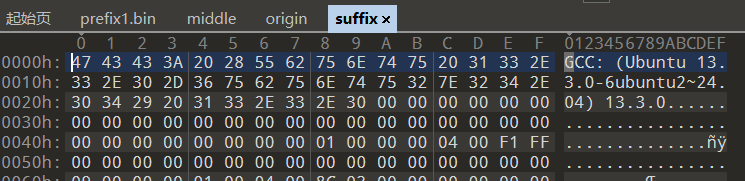
截取ori中第二个字符串前面的内容
head -c 12544 origin > tmp1根据prefix1和prefix2可知,针对第一个字符串还需填充40字节才能达到200字节
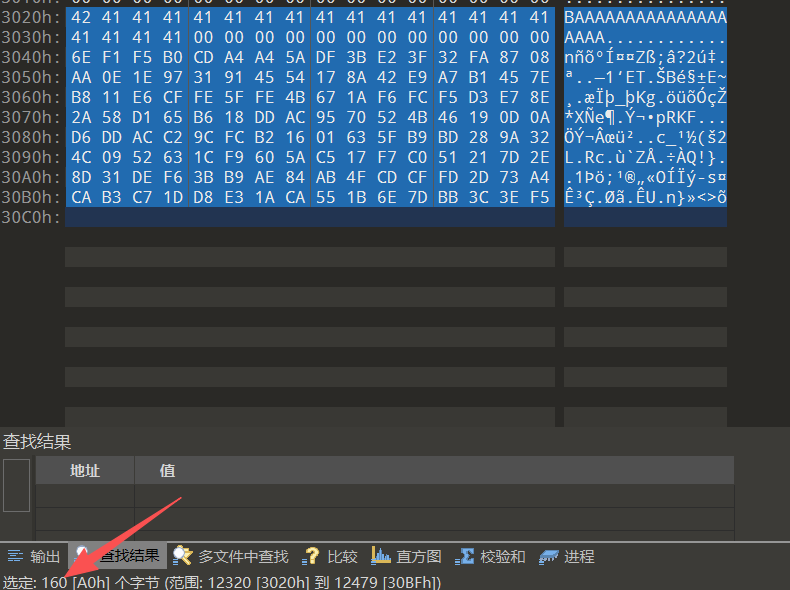
截取tmp1中的0x00
tail -c 40 tmp1 > tmp0拼接prefix1
cat tmp >> prefix1.bincat middle >> prefix1.bincat tmp0 >> prefix1.bin # 注意该命令有误,详情见下文cat suffix >> prefix1.bin
结果出错了??
但此时应该预期输出benign code,查看二进制文件的两个字符串也确实是相等的
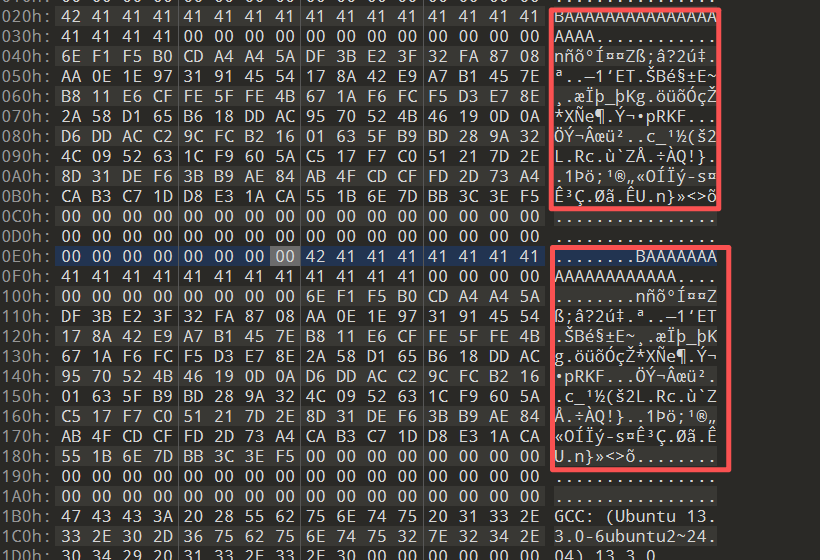
那么为什么呢???:anguished::anguished::anguished:
经过查看origin文件可知:
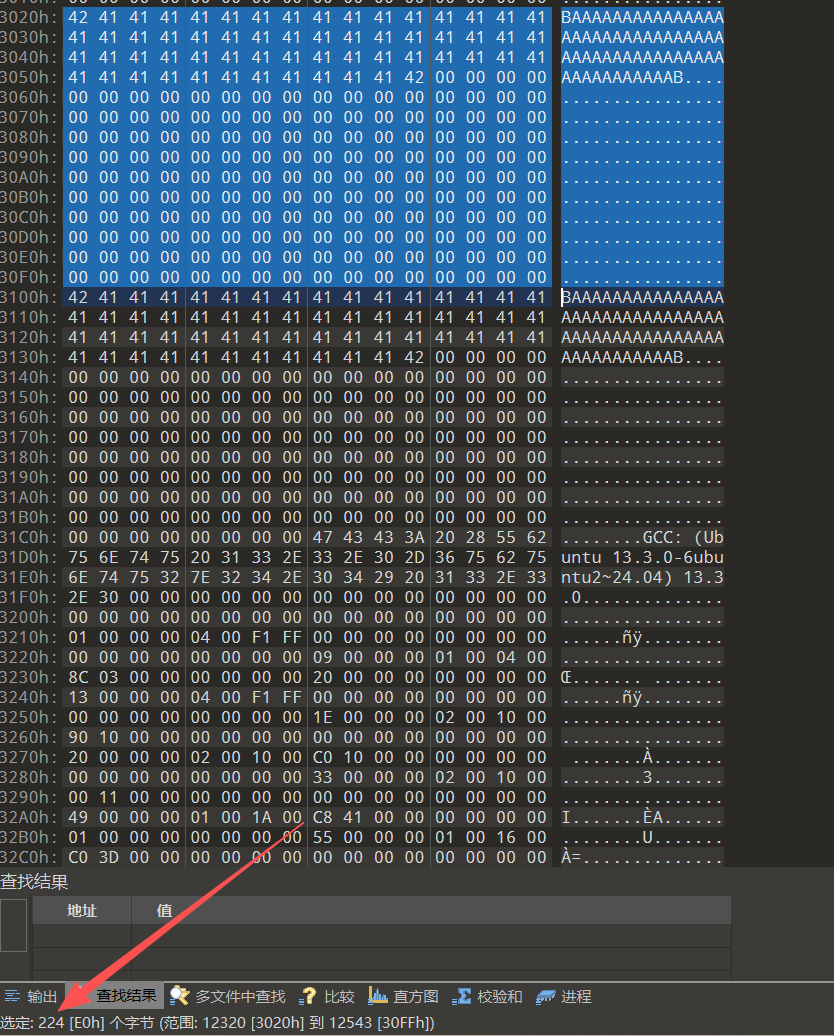
两个字符串的内存空间并非连续,而是多出了24字节的空闲空间,所以需要对补充0x00时做出修改:
tail -c 64 tmp1 > tmpcat tmp >> prefix1.bin再次运行:
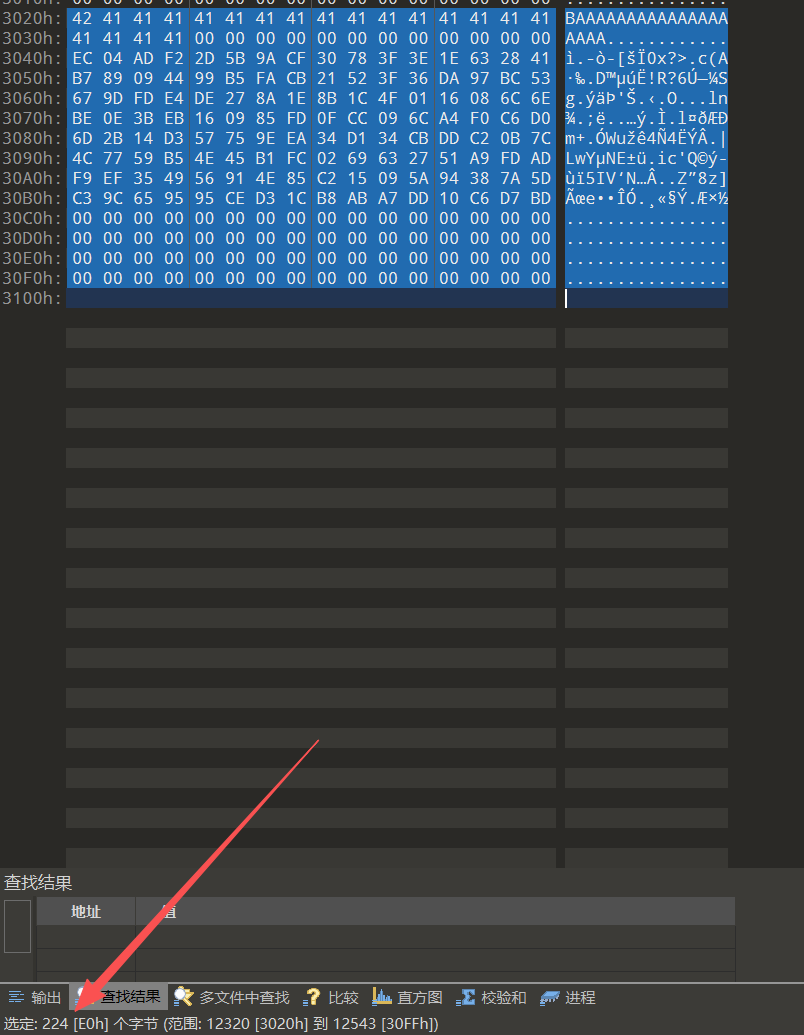
成功补全!
继续拼接:
cat middle >> prefix1.bincat tmp0 >> prefix1.bin # 注意:这里仍是补充40字节!!!cat suffix >> prefix1.bin
结果符合预期
拼接prefix2
cat tmp >> prefix2.bincat middle >> prefix2.bincat tmp0 >> prefix2.bincat suffix >> prefix2.bin
结果符合预期

MD5值相同
总结
根本原理是先生成两个MD5相同的前缀文件,之后对两个文件补充相同后缀,即可使最终的两个文件的MD5值相同
MD5 的内部结构和已知的密码学弱点使得能够构造出两份不同的消息(包括可执行文件),而让它们经过 MD5 哈希后产生完全相同的 128 位摘要。攻击者利用对 MD5 压缩函数的差分分析与碰撞构造技术,在文件中插入或安排特殊的“碰撞块”,使得哈希运算的中间状态在最终输出时一致,从而得到相同哈希但不同文件内容与不同执行行为的结果。
消息摘要函数(hash function)如 MD5、SHA-256 等,将任意长度输入映射为固定长度输出。大多数经典哈希函数采用迭代结构:先将消息按固定大小的分组分块,然后对每一块调用一个压缩函数(compression function),用上一块的输出作为下一块的输入。最终哈希值就是最后一个块处理后的内部状态。因此,控制或操纵某些消息块可以影响中间状态的传播,从而影响最终结果。
碰撞指的是两条不同消息 (m) 和 (m’) 具有相同哈希值:。一般情况下,对抗碰撞的要求是哈希函数在抽象上难以找到这类不同消息。经典的碰撞攻击通常构造所谓的“相同前缀碰撞”,即从某个共同前缀之后插入一对预先计算好的不同块,使得后续内部状态抵消,最终哈希相同。更强的攻击是 chosen‑prefix collision (CPC):攻击者可以为任意两个不同的前缀 (P) 和 (Q) 分别生成配套的碰撞块 ,使得 。CPC 的危险性在于它允许攻击者从两个任意起始文件出发,生成哈希相同但内容不同的两个完整文件。
MD5 的压缩函数存在可被差分分析利用的结构性弱点。研究者发现了使得两个不同分组序列在内部状态上产生特定差分并在后续步骤“相互抵消”的方法,这些差分路径大幅降低了找到碰撞所需的复杂度。历史上已经有多次实用攻击(包括对证书系统的滥用)验证了 MD5 的不可用性。因此,MD5 不再被视为具有碰撞抗性的安全哈希函数,尤其不该用于数字证书、签名或任何需抗碰撞的安全场景
可执行文件(如 ELF、PE、Mach‑O)通常由多个节和段组成:代码区、数据区、符号/调试区、资源区、对齐填充、重定位信息等。这些结构提供了许多可被利用的空间:
- 非关键区放置碰撞块:将碰撞数据放在不会被 loader 或运行时直接执行或解释的节里(例如调试信息、资源区、注释或未被引用的数据段),可以保持程序运行逻辑不受影响。
- 利用对齐与填充:二进制通常包含为了对齐而存在的填充字节,这些位置可以容纳碰撞块。
- 控制入口/重定位:通过精心安排段表和入口点,文件可以在保持合法加载的同时,包含差异化的 payload,使两个文件运行不同逻辑。
- 构造合法但行为不同的布局:攻击者可在保证两份文件被操作系统接受为“合法可执行文件”的前提下,让两份文件在运行时走向不同路径(例如修改常量、字符串、跳转表或初始化数据),同时使 MD5 值相同。
构建步骤:先确定两个不同的“前缀”二进制(即两个不同的起始可执行文件),然后为每个前缀生成专门的碰撞块,使得在这些碰撞块影响之后,哈希的内部状态一致;最后再附加各自的后缀(payload),以实现不同的运行行为。
关键要求是:碰撞块必须被安排在不会破坏 loader 检查且能够被精确控制的位置,同时保证最终的文件格式仍被操作系统接受。